"A sieve, or sifter, separates wanted elements from unwanted material using a woven screen such as a mesh or net."
Source: Wikipedia
Sieve allows Web data to be filtered according to different data quality assessment policies and provides for fusing Web data according to different conflict resolution methods.
News
- 13/02/2014: Sieve new version released with LDIF 0.5.2, including Fusion Policy Learner, new quality assessment scores and fusion functions, various bugfixes.
- 19/12/2013: Fusion Policy Learner module has been added to Sieve.
- 14/11/2012: Sieve new version released with LDIF 0.5.1, including various bugfixes.
- 12/08/2012: Bugfixes; Additional Functions; Quality Assessment and Data Fusion modules integrated with the LOD2 Stack.
- 03/04/2012: First implementation included in LDIF 0.5.
- 30/03/2012: Paper about Sieve presented at the LWDM workshop at EDBT'12. [ pdf ] [ slides ]
- 29/02/2012: Conceptual design and implementation of metrics released.
Contents
1. About Sieve
The Web of Linked Data grows rapidly and contains data originating from hundreds of data sources. The quality of data from those sources is very diverse, as values may be out of date, incomplete or incorrect. Moreover, data sources may provide conflicting values for the same properties.
In order for Linked Data applications to consume data from this global data space in an integrated fashion, a number of challenges have to be overcome. The Linked Data Integration Framework (LDIF) provides a modular architecture that homogenizes Web data into a target representation as configured by the user. LDIF includes Data Access, Schema Mapping, Identity Resolution and Data Output modules. This document describes Sieve, which adds quality assessment and data fusion capabilities to the LDIF architecture.
Sieve uses metadata about named graphs (e.g. provenance) in order to assess data quality as defined by users. Sieve is agnostic to provenance vocabulary and quality models. Through its configuration files, Sieve is able to access provenance expressed in different ways, and uses customizable scoring functions to output data quality descriptors according to a user-specified data-quality vocabulary.
Based on these quality descriptors (and/or optionally other descriptors computed elsewhere), Sieve can use configurable FusionFunctions to clean the data according to task-specific requirements.
2. Sieve within LDIF Architecture
The figure below shows the schematic architecture of Linked Data applications that implement the crawling/data warehousing pattern. The figure highlights the steps of the data integration process that are currently supported by LDIF.
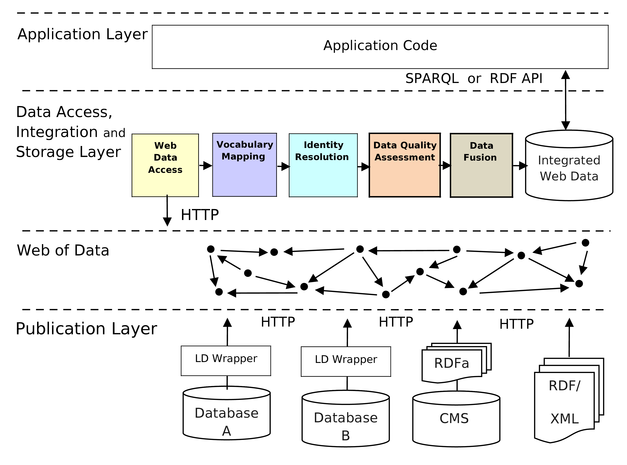
Sieve is employed as the quality evaluation module in LDIF (see figure 1). The data cleaning procedure in Sieve works in two steps. The first step, Quality Assessment, associates quality-scores to the named graphs that are used in LDIF for provenance tracking and that group subsets of triples together. The second step uses this metadata to decide on how to fuse conflicting property values according to user configuration.
3. Quality Assessment
Data is considered to be high quality "if they are fit for their intended uses in operations, decision making and planning." (J. M. Juran) According to this task-dependent view on data quality, we realize the quality assessment task through a configurable module relying on multifaceted quality descriptions based on quality indicators.
- Data Quality Indicator
- An aspect of a data item or data set that may give an indication to the user of the suitability of the data for some intended use. The types of information which may be used as quality indicators are very diverse. Besides the information to be assessed, scoring functions may rely on meta-information about the circumstances in which information was created or will be used, on background information about the information provider, or on ratings provided by the information consumers themselves, other information consumers, or domain experts.
- Scoring Function
- An implementation that, based on indicators, generates a score to be evaluated by the user in the process of deciding on the suitability of the data for some intended use. There may be a choice of several alternative or combined scoring functions for producing a score for a given indicator. Depending on the quality dimension to be assessed and the chosen quality indicators, scoring functions range from simple comparisons, like "assign true if the quality indicator has a value greater than X", over set functions, like "assign true if the indicator is in the set Y", aggregation functions, like "count or sum up all indicator values", to more complex statistical functions, text-analysis, or network-analysis methods.
- Assessment Metric
- Is a procedure for measuring an information quality dimension. Assessment metrics rely on a set of quality indicators and calculate an assessment score from these indicators using a scoring function. Information quality assessment metrics can be classified into three categories according to the type of information that is used as quality indicator: content-based metrics, context-based metrics and rating-based metrics.
- Aggregate Metric
- User can specify aggregate assessment metrics built out of individual assessment metrics. These aggregations produce new assessment values through the average, sum, max, min or threshold functions applied to a set of assessment metrics. Aggregate assessment metrics are better visualized as trees, where an aggregation function is applied to the leaves and combined up the tree until a single value is obtained. The functions to be applied at each branch are specified by the users.
Quality Assessment Configuration
A Quality Assessment Job updates the metadata about external sources in the local cache with by computing quality metrics and it is configured with an XML document, whose structure is described by this XML Schema.
A typical configuration document looks like this:
<QualityAssessment name="Recent and Reputable is Best"
description="The idea that more recent articles from Wikipedia
could capture better values that change over time (recency),
while if there is a conflict between two Wikipedias, trust the one
which is more likely to have the right answer (reputation).">
<AssessmentMetric id="sieve:reputation">
<ScoringFunction class="ScoredList">
<Param name="list"
value="http://pt.wikipedia.org http://en.wikipedia.org
http://es.wikipedia.org http://fr.wikipedia.org http://de.wikipedia.org"/>
</ScoringFunction>
</AssessmentMetric>
<AssessmentMetric id="sieve:recency">
<ScoringFunction class="TimeCloseness">
<Param name="timeSpan" value="50000"/>
<Input path="?GRAPH/ldif:lastUpdate"/>
</ScoringFunction>
</AssessmentMetric>
</QualityAssessment>
It has the following elements:
- QualityAssessment - groups a number of assessment metrics into a quality assessment "policy". Users can give it a name which should be unique, and a description to help to explain the intentions of this policy.
- AssessmentMetric - describes a simple assessment metric. Each simple AssessmentMetric element specifies a unique identifier for the aspect of quality that is being assessed (through the attribute indicator) and a ScoringFunction element that will provide a real valued assessment (between 0 and 1) of this indicator.
- AggregateMetric - describes an aggregation function over a number of simple assessment metrics.
- ScoringFunction - configures the input of a java/scala class implementing a scoring function. Each scoring function takes in a number of input parameters (Param, Input or EnvironmentVariable) and generates a real value between 0 and 1 based on this input. The Param element is used for static values, Input is used for accessing values in the data being consumed by LDIF, and EnvironmentVariable accesses values stored in the system (e.g. username, date, etc.).
- Input - specifies either a path or a SPARQL query to access metadata (e.g. provenance) about named graphs. This metadata will be provided as input to a scoring function, which will then produce additional metadata in the form of indicators. A path attribute contains a path expression (series of variables and RDF properties separated by "/") that indicate how to select applicable metadata from the input. Conventionally, for path attributes within ScoringFunction elements, the paths start with a variable named ?GRAPH.
Input
In its most basic form, the input for the quality assessment task is the LDIF provenance metadata.
When LDIF imports a new data source, it generates ldif:ImportedGraph descriptions for all graphs in the input (see Data Import for module-specific details).
Sieve will (by default) mash that with any other graph metadata provided as input, and feed that through the scoring functions defined in the configuration.
This allows the configuration to use automatically computed metadata by LDIF, as well as metadata from the original source, or from other third-parties.
Examples of such third-party metadata include ratings, prominence statistics, etc.
Optionally, if all the metadata you need is contained within the LDIF provenance graph, you can set the configuration property qualityFromProvenanceOnly=true in integration.properties.
This will instruct Sieve to limit the input data to the quality module to only the provenance graph, reducing computation effort, time and output size.
Available Scoring Functions
There is a vast number of possible scoring functions for quality assessment. We do not attempt to implement all of them. The currently implemented scoring functions are:
- TimeCloseness: measures the distance from the input date (obtained from the input metadata through a path expression) to the current (system) date. Dates outside the range (expressed in number of days) receive value 0, and dates that are more recent receive values closer to 1. Example input:
<ScoringFunction class="TimeCloseness"> <Param name="range" value="7"/> <Input path="?GRAPH/ldif:lastUpdate"/> </ScoringFunction>
Example output: 0.85 (assuming the last update was yesterday).
TimeCloseness can be used for indicators such as freshness (last updated) and recency (creation date). - ScoredList: assigns decreasing, uniformly distributed, real values to each graph URI provided as space-separated list.
Example input:
<ScoringFunction class="ScoredList"> <Param name="list" value="http://en.wikipedia.org http://pt.wikipedia.org http://de.wikipedia.org http://es.wikipedia.org"/> </ScoringFunction>Example output: {http://en.wikipedia.org=1, http://pt.wikipedia.org=0.75, http://de.wikipedia.org=0.5, http://es.wikipedia.org=0.25, http://fr.wikipedia.org=0} - ScoredPrefixList: assigns decreasing, uniformly distributed, real values to each graph URI that matches one of the provided (as space-separated list) prefixes.
Example input:
<ScoringFunction class="ScoredPrefixList"> <Param name="list" value="http://en.wikipedia.org http://pt.wikipedia.org http://de.wikipedia.org http://es.wikipedia.org"/> </ScoringFunction>Example output: {http://en.wikipedia.org/wiki/Berlin=1, http://pt.wikipedia.org/wiki/Berlin=0.75, http://de.wikipedia.org/wiki/Berlin=0.5, http://es.wikipedia.org/wiki/Berlin=0.25, http://fr.wikipedia.org/wiki/Berlin=0} - Threshold: assigns 1 if the value of the indicator provided as input is higher than a threshold specified as parameter, 0 otherwise.
<ScoringFunction class="Threshold"> <Param name="threshold" value="5"/> <Input path="?GRAPH/example:numberOfEdits"/> </ScoringFunction>
Example output: {http://en.wikipedia.org/wiki/DBpedia=1, http://pt.wikipedia.org/wiki/DBpedia=0} - Interval: assigns 1 if the value of the indicator provided as input is within the interval specified as parameter, 0 otherwise.
<ScoringFunction class="Interval"> <Param name="from" value="6"/> <Param name="to" value="42"/> <Input path="?GRAPH/provenance:whatever"/> </ScoringFunction>
- NormalizedCount: normalizes indicator values by the threshold provided as a parameter, if the value of an indicator is greater than the threshold outputs 1.0.
<ScoringFunction class="NormalizedCount"> <Param name="maxCount" value="100"/> <Input path="?GRAPH/example:numberOfEdits"/> </ScoringFunction>
ScoringFunction classes. The class should implement ldif.modules.sieve.quality.ScoringFunction, which defines the method fromXML (a method to create a new object of the class given the configuration parameters) and the method score (which will be called at runtime to perform quality assessment based on a number of metadata values). Method signatures (in Scala):
trait ScoringFunction {
def score(graphId: NodeTrait, metadataValues: Traversable[IndexedSeq[NodeTrait]]): Double
}
object ScoringFunction {
def fromXML(node: Node) : ScoringFunction
}
Output
The quality-describing metadata computed by this step can be output and stored as an extension to the LDIF Provenance Graph.
In this case, all non-zero scores are written out as quads, for each graph evaluated in LDIF. Metrics with score=0.0 are omitted, as in Sieve a missing quality assessment is equivalent to a zero score.
If you wish to omit all quality scores from the final output (e.g. to reduce output size), you can set the configuration property outputQualityScores=false in integration.properties.
Regardless, the quality scores will always be passed on to the fusion module, if a Fusion configuration exists.
enwiki:Juiz_de_Fora sieve:recency "0.4" ldif:provenance . ptwiki:Juiz_de_Fora sieve:recency "0.8" ldif:provenance . enwiki:Juiz_de_Fora sieve:reputation "0.75" ldif:provenance . ptwiki:Juiz_de_Fora sieve:reputation "0.25" ldif:provenance .
4. Data Fusion
Data Fusion combines data from multiple sources and aims to remove or transform conflicting values towards a clean representation.
In Sieve, the data fusion step relies on quality metadata generated by the Quality Assessment Module, and a configuration file that instructs which fusion functions to apply for each property. A data fusion function takes in all values for each property from all data sources together with the quality scores that have been previously calculated by the Data Quality Assessment Module. In order to output a clean value for each property, it applies fusion fuctions implementing decisions such as: take the highest scored value for a given quality assessment metric, take the average of values, etc.
Fusion Configuration
A Data Fusion Job is configured with an XML document, whose structure is described by this XML Schema.
A typical configuration document looks like this:
<Fusion name="Fusion strategy for DBpedia City Entities"
description="The idea is to use values from multiple DBpedia languages to improve the quality of data about cities.">
<Class name="dbpedia:City">
<Property name="dbpedia:areaTotal">
<FusionFunction class="KeepValueWithHighestScore" metric="sieve:lastUpdated" />
</Property>
<Property name="dbpedia:population">
<FusionFunction class="Average" />
</Property>
<Property name="dbpedia:name">
<FusionFunction class="KeepValueWithHighestScore" metric="sieve:reputation" />
</Property>
</Class>
</Fusion>
It has the following elements:
- Fusion - describes a Data Fusion policy. Users can give it a name which should be unique, and a description to help to explain the intentions of this policy. Each Fusion defines which data to fuse through Class and Property sub-elements, and which fusion functions to apply through FusionFunction elements.
- Class - defines a subset of the input by selecting all instances of the class provided in the attribute name.
- Property - defines which FusionFunction should be applied to the values of a given RDF property. The property qName should be given in the attribute name, and the FusionFunction element must be specified as a child of Property.
- FusionFunction - specifies in the name attribute which java/scala class should be used to fuse values for a given property. It can take in a number of Parameter elements, which specify name of the parameter and value for that parameter. The framework is extensible, and users can define their own set of FusionFunction classes. The class should implement ldif.modules.sieve.fusion.FusionFunction, which defines the method fromXML (a method to create a new object of the class given the configuration parameters) and the method fuse (which will be called at runtime to perform fusion based on a number of values and quality assessment metadata). Method signatures (in Scala):
class FusionFunction(val metricId: String="") { def fuse(values: Traversable[IndexedSeq[NodeTrait]], quality: QualityAssessment) : Traversable[IndexedSeq[NodeTrait]] } object FusionFunction { def fromXML(node: Node) : FusionFunction }
Available Fusion Functions
The currently implemented fusion functions are:
- PassItOn: does nothing, passes values on to the next component in the pipeline.
- KeepFirst: keeps the value with the highest score for a given quality assessment metric. In case of ties, the function keeps the first value in the order of input.
<FusionFunction class="KeepFirst" metric="sieve:reputation"/>
- KeepAllValuesByQualityScore: similar to KeepFirst, but in case of ties, it keeps all values with the highest score.
- KeepLast: keeps the value with the lowest value for a given quality assessment metric. In case of ties, the function keeps the first in order of input. Used to invert scores, e.g. to invert TimeCloseness to consider the most experienced author (active since the earliest date).
- Average: takes the average of all input data for a given property.
<FusionFunction class="Average"/>
- Maximum: takes the maximum of all input data for a given property.
- Voting: picks the value that appeared most frequently across sources. Each named graph has one vote, the most voted value is chosen.
- WeightedVoting: picks the value that appeared most frequently across highly rated sources. Each named graph has one vote proportional to its score for a given quality metric, the value with the highest aggregated scores is chosen.
5. Examples
This section provides a Sieve usage example. We will explore the use case of integrating information about cities coming from different DBpedia editions. We have included the configuration files for this example in our distribution under ldif/examples/lwdm2012.
Here is how you can run this example:
- download the latest release
- unpack the archive and change into the extracted directory
ldif-0.5.1 - to run this example:
- under Linux / Mac OS type:
bin/ldif examples/lwdm2012/schedulerConfig.xml
- under Windows type:
bin\ldif.bat examples\lwdm2012\schedulerConfig.xml
- under Linux / Mac OS type:
The directory ImportJobs contains a list of configuration files that will download the data into your server. One example configuration is shown below:
<importJob >
<internalId>pt.dbpedia.org</internalId>
<dataSource>DBpedia</dataSource>
<refreshSchedule>onStartup</refreshSchedule>
<tripleImportJob>
<dumpLocation>http://sieve.wbsg.de/download/lwdm2012/pt.nq.bz2</dumpLocation>
</tripleImportJob>
</importJob>
The directory sieve contains configuration for quality assessment and fusion of these data. For this use case, we consider reputation and recency to be important quality aspects.
We will assign higher reputation to data coming from the English Wikipedia (because it is the largest and most viewed), followed by the Portuguese (because it's the most relevant for the use case), Spanish, French and German (in subjective order of language similarity to Portuguese).
Recency will be measured by looking at the lastUpdated property, which was extracted from Wikipedia Dumps.
<Sieve xmlns="http://www4.wiwiss.fu-berlin.de/ldif/">
<Prefixes>
<Prefix id="dbpedia-owl" namespace="http://dbpedia.org/ontology/"/>
<Prefix id="dbpedia" namespace="http://dbpedia.org/resource/"/>
<Prefix id="sieve" namespace="http://sieve.wbsg.de/vocab/"/>
</Prefixes>
<QualityAssessment name="Recent and Reputable is Best"
description="The idea that more recent articles from Wikipedia
could capture better values that change over time (recency),
while if there is a conflict between two Wikipedias, trust the one
which is more likely to have the right answer (reputation).">
<AssessmentMetric id="sieve:recency">
<ScoringFunction class="TimeCloseness">
<Param name="timeSpan" value="500"/>
<Input path="?GRAPH/ldif:lastUpdate"/>
</ScoringFunction>
</AssessmentMetric>
<AssessmentMetric id="sieve:reputation">
<ScoringFunction class="ScoredList">
<Param name="list"
value="http://en.wikipedia.org http://pt.wikipedia.org http://es.wikipedia.org http://fr.wikipedia.org"/>
</ScoringFunction>
</AssessmentMetric>
</QualityAssessment>
<Fusion name="Fusion strategy for DBpedia City Entities"
description="The idea is to use values from multiple DBpedia languages to improve the quality of data about cities.">
<Class name="dbpedia-owl:Settlement">
<Property name="dbpedia-owl:areaTotal">
<FusionFunction class="KeepFirst" metric="sieve:recency"/>
</Property>
<Property name="dbpedia-owl:populationTotal">
<FusionFunction class="KeepFirst" metric="sieve:recency"/>
</Property>
<Property name="dbpedia-owl:foundingDate">
<FusionFunction class="KeepFirst" metric="sieve:reputation"/>
</Property>
</Class>
</Fusion>
</Sieve>
After running you should obtain results saved in a file called "integrated_cities.nq". This file name is configurable in integrationJob.xml.
The output contains all the fused properties and every other property that came in the input for which no fusion was specified.
Some example data for fused properties:
<http://dbpedia.org/resource/Cachoeiras_de_Macacu> <http://dbpedia.org/ontology/areaTotal> "9.55806E11"^^<http://www.w3.org/2001/XMLSchema#double> <http://pt.wikipedia.org/wiki/Cachoeiras_de_Macacu> . <http://dbpedia.org/resource/Cachoeiras_de_Macacu> <http://dbpedia.org/ontology/populationTotal> "54370"^^<http://www.w3.org/2001/XMLSchema#nonNegativeInteger> <http://pt.wikipedia.org/wiki/Cachoeiras_de_Macacu> . <http://dbpedia.org/resource/%C3%81lvares_Florence> <http://dbpedia.org/ontology/areaTotal> "3.62E8"^^<http://www.w3.org/2001/XMLSchema#double> <http://pt.wikipedia.org/wiki/%C3%81lvares_Florence> . <http://dbpedia.org/resource/%C3%81lvares_Florence> <http://dbpedia.org/ontology/populationTotal> "3897"^^<http://www.w3.org/2001/XMLSchema#integer> <http://en.wikipedia.org/wiki/%C3%81lvares_Florence> . <http://dbpedia.org/resource/Ant%C3%B4nio_Prado> <http://dbpedia.org/ontology/areaTotal> "3.47616E8"^^<http://www.w3.org/2001/XMLSchema#double> <http://en.wikipedia.org/wiki/Ant%C3%B4nio_Prado> . <http://dbpedia.org/resource/Ant%C3%B4nio_Prado> <http://dbpedia.org/ontology/populationTotal> "14159"^^<http://www.w3.org/2001/XMLSchema#integer> <http://en.wikipedia.org/wiki/Ant%C3%B4nio_Prado> . <http://dbpedia.org/resource/Ant%C3%B4nio_Prado> <http://dbpedia.org/ontology/foundingDate> "1899-02-11"^^<http://www.w3.org/2001/XMLSchema#date> <http://en.wikipedia.org/wiki/Ant%C3%B4nio_Prado> .
If you choose to output quality scores, then you should also notice many triples assigned to your graph URIs, like this:
<http://es.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/reputation> "0.5"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://pt.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/reputation> "0.75"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://fr.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/reputation> "0.25"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://en.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/reputation> "1.0"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://de.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/recency> "0.9956"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://en.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/recency> "0.9955"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://es.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/recency> "0.9648"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://fr.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/recency> "0.9956"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> . <http://pt.wikipedia.org/wiki/Rio_de_Janeiro> <http://sieve.wbsg.de/vocab/recency> "0.9953"^^<http://www.w3.org/2001/XMLSchema#double> <http://www4.wiwiss.fu-berlin.de/ldif/provenance> .
Now you can play with the assessment metrics and the fusion functions and check the differences in the output. You may also add your own data via an ImportJob, and see how that changes the results. Have fun sifting data for a better Web!
6. Source Code and Development
The latest source code is available from the LDIF development page on GitHub.
The framework can be used under the terms of the Apache Software License.
7. Support and Feedback
For questions and feedback please use the LDIF Google Group.
8. References
- Pablo N. Mendes, Hannes Mühleisen, Christian Bizer. Sieve: Linked Data Quality Assessment and Fusion. 2nd International Workshop on Linked Web Data Management (LWDM 2012) at the 15th International Conference on Extending Database Technology, EDBT 2012. [pdf]
@inproceedings{lwdm12mendes, booktitle = {2nd International Workshop on Linked Web Data Management (LWDM 2012) at the 15th International Conference on Extending Database Technology, EDBT 2012}, month = {March}, title = {{Sieve: Linked Data Quality Assessment and Fusion}}, author = {Mendes, Pablo N. and M\"{u}hleisen, Hannes and Bizer, Christian} year = {2012}, pages = {to appear}, url = {http://www.wiwiss.fu-berlin.de/en/institute/pwo/bizer/research/publications/Mendes-Muehleisen-Bizer-Sieve-LWDM2012.pdf}, howpublished = {invited paper} }
9. Acknowledgments
This work was supported in part by the EU FP7 grants LOD2 - Creating Knowledge out of Interlinked Data (Grant No. 257943) and PlanetData - A European Network of Excellence on Large-Scale Data Management (Grant No. 257641) as well as by Vulcan Inc. as part of its Project Halo.
WooFunction icon set licensed under GNU General Public License.